11 KiB
介绍
我能听到你的声音,幽灵。 逃跑并不能让你逃脱我的 粒子滤波器!
帕克曼一生都在逃离鬼魂,但事情并不总是这样。传说许多年前,帕克曼的曾祖父帕克曼爷爷学会了猎杀鬼魂。然而,他被自己的力量蒙蔽了双眼,只能通过鬼魂的撞击声和叮当声来追踪它们。
在这个项目中,你将设计 Pacman agent,使用传感器来定位和吃掉隐形幽灵。您将从定位单个静止的幽灵进步到以无情的效率猎杀多个移动幽灵群。
你需要补全的代码文件有:
bustersAgents.pyinference.py: 用于利用鬼魂的声音来追踪鬼魂随时间变化的代码。factorOperations.py: 计算新的联合或边值化概率表的操作。
你可以阅读并参考来帮助你实现代码的文件有:
bayesNet.py:BayesNet和Factor类。
你可以忽略其他支持文件。
Ghostbusters(捉鬼敢死队) and Bayes Nets
在《捉鬼敢死队》中,目标是追捕那些处于惊恐状态(能吃)但看不见的鬼魂。 Pacman 一如既往地足智多谋,他装备了声纳(耳朵),可以提供到每个鬼魂的曼哈顿距离的噪声读数。当吃豆人吃掉所有鬼魂时,游戏结束。要开始游戏,可以使用键盘进行操作。
python busters.py
彩色方块表示根据提供给吃豆人的噪声距离读数,每个鬼魂可能出现的位置。显示底部的噪声距离总是非负的,并且总是与真实距离相差 7 以内。距离读数的概率随着与真实距离的差异呈指数下降。
在这个项目中,你的主要任务是实现推理以追踪鬼魂。对于上面的基于键盘的游戏,默认为你实现了一种粗略的推理形式:所有鬼魂可能存在的方格都被鬼魂的颜色遮蔽。显然,我们希望能更好地估计鬼魂的位置。幸运的是,贝叶斯网络为我们提供了强大的工具,能够最大限度地利用我们拥有的信息。在这个项目的其余部分中,你将使用贝叶斯网络实现精确和近似推理算法。这个项目具有挑战性,因此我们鼓励你尽早开始并在必要时寻求帮助。
在使用自动评分器观看和调试代码时,了解自动评分器的工作原理将很有帮助。这个项目中有两种类型的测试,可以通过 test_cases 文件夹子目录中的 .test 文件来区分。对于 DoubleInferenceAgentTest 类的测试,你将看到代码生成的推理分布的可视化,但所有吃豆人的动作都将根据工作人员实现的动作预先选择。这是为了允许将你的分布与工作人员的分布进行比较。第二种测试是 GameScoreTest,在这种测试中,你的 BustersAgent 将实际为吃豆人选择动作,你将观看你的吃豆人游戏并获胜。
在这个项目中,如果运行带图形的测试,自动评分器有时可能会超时。为了准确判断你的代码是否足够高效,你应该使用 --no-graphics 标志运行测试。如果使用此标志自动评分器通过了测试,即使带图形的自动评分器超时,你也会获得满分。
贝叶斯网络和因子
首先,看看 bayesNet.py 文件,了解你将要使用的类——贝叶斯网络(BayesNet)和因子(Factor)。你还可以运行这个文件,查看一个贝叶斯网络及其相关因子的示例:python bayesNet.py。
你应该查看 printStarterBayesNet 函数——其中有一些有用的注释,可以让你的工作更轻松。
该函数创建的贝叶斯网络如下所示:
(Raining –> Traffic <– Ballgame)
下面是术语的摘要:
贝叶斯网络(Bayes Net):这是一个将概率模型表示为有向无环图(DAG)和一组条件概率表(每个变量一个)的表示。上面的交通贝叶斯网络是一个示例。
因子(Factor):这存储了一个概率表,尽管表中条目的总和不一定是1。因子的通用形式是
f(X_1, \ldots, X_m, y_1, \ldots, y_n \mid Z_1, \ldots, Z_p, w_1, \ldots, w_q)
请记住,小写变量已经被赋值。对于每个可能的 X_i 和 Z_j 变量的赋值,因子存储一个数字。Z_j 和 w_k 变量被称为条件变量,而 X_i 和 y_l 变量是非条件变量。
条件概率表(CPT):这是一个满足两个属性的因子:
- 条目的总和对于每个条件变量的赋值必须为1。
- 只有一个非条件变量。交通贝叶斯网络存储了以下CPT:
P(Raining), P(Ballgame), P(Traffic \mid Ballgame, Raining)
Q1: Bayes Net Structure
请在 inference.py 中实现 constructBayesNet 函数。它构建了一个具有以下结构的空贝叶斯网络。一个贝叶斯网络在没有实际概率的情况下是不完整的,但因子由工作人员代码单独定义和分配;你不需要担心这些。如果你感兴趣,可以在 bayesNet.py 中查看 printStarterBayesNet 的工作示例。阅读这个函数对于完成这个问题也很有帮助。
简化的捉鬼世界是根据以下贝叶斯网络生成的:
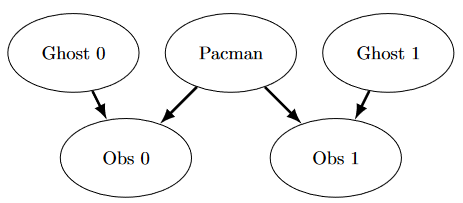
这个看起来很复杂,但不用担心!我们会一步一步来。正如 constructBayesNet 代码中所描述的那样,我们通过列出所有变量、它们的值以及它们之间的边来构建空结构。这个图显示了变量和边,但它们的域是什么呢?
- 根据图添加变量和边。
- 吃豆人和两个鬼魂可以在网格中的任何地方(我们在这里忽略墙壁)。为这些添加所有可能的位置元组。
- 这里的观察值是非负的,等于吃豆人与鬼魂之间的曼哈顿距离
\pm噪声。
评分:要测试和调试你的代码,请运行
python autograder.py -q q1
Q2: Join Factors
请在 factorOperations.py 中实现 joinFactors 函数。该函数接收一个因子列表并返回一个新因子,其概率条目是输入因子对应行的乘积。
joinFactors 可以用作乘积规则,例如,如果我们有一个形式为 P(X \mid Y) 的因子和另一个形式为 P(Y) 的因子,那么合并这些因子将得到 (P(X, Y))。因此,joinFactors 允许我们为条件变量(在本例中是 (Y))加入概率。但是,你不应该假设 joinFactors 只对概率表调用——也可以对行和不等于1的因子调用 joinFactors。
要测试和调试你的代码,请运行
python autograder.py -q q2
在调试期间运行特定测试可能会很有用,可以只看到一组因子的输出。例如,要仅运行第一个测试,请运行:
python autograder.py -t test_cases/q2/1-product-rule
提示和观察:
-
你的
joinFactors应返回一个新因子。 -
以下是
joinFactors可以执行的操作示例:\text{joinFactors}(P(X \mid Y), P(Y)) = P(X, Y)\text{joinFactors}(P(V, W \mid X, Y, Z), P(X, Y \mid Z)) = P(V, W, X, Y \mid Z)\text{joinFactors}(P(X \mid Y, Z), P(Y)) = P(X, Y \mid Z)\text{joinFactors}(P(V \mid W), P(X \mid Y), P(Z)) = P(V, X, Z \mid W, Y)
-
对于一般的
joinFactors操作,返回的因子中哪些变量是非条件变量?哪些变量是条件变量? -
因子(
Factor)存储一个variableDomainsDict,它将每个变量映射到它可以取的值(其域)列表。因子从其实例化的贝叶斯网络(BayesNet)获取其variableDomainsDict。因此,它包含贝叶斯网络的所有变量,而不仅仅是因子中使用的非条件和条件变量。对于这个问题,你可以假设所有输入因子都来自同一个贝叶斯网络,因此它们的variableDomainsDict都是相同的。
Q3: Eliminate (not ghosts yet)
请在 factorOperations.py 中实现 eliminate 函数。它接收一个因子和一个要消除的变量,并返回一个不包含该变量的新因子。这对应于对因子中仅在被消除变量的值上有所不同的所有条目求和。
要测试和调试你的代码,请运行
python autograder.py -q q3
在调试期间运行特定测试可能会很有用,可以只看到一组因子的输出。例如,要仅运行第一个测试,请运行:
python autograder.py -t test_cases/q3/1-simple-eliminate
提示和观察:
-
你的
eliminate应返回一个新因子(Factor)。 -
eliminate可以用于从概率表中边缘化变量。例如:\text{eliminate}(P(X, Y \mid Z), Y) = P(X \mid Z)\text{eliminate}(P(X, Y \mid Z), X) = P(Y \mid Z)
-
对于一般的
eliminate操作,返回的因子中哪些变量是非条件变量?哪些变量是条件变量? -
请记住,因子(
Factor)存储原始贝叶斯网络(BayesNet)的variableDomainsDict,而不仅仅是它们使用的非条件和条件变量。因此,返回的因子应具有与输入因子相同的variableDomainsDict。
Q4: Variable Elimination
请在 inference.py 中实现 inferenceByVariableElimination 函数。它回答一个概率查询,该查询使用贝叶斯网络(BayesNet)表示,包含一个查询变量列表和证据。
评分:要测试和调试你的代码,请运行
python autograder.py -q q4
在调试期间运行特定测试可能会很有用,可以只看到一组因子的输出。例如,要仅运行第一个测试,请运行:
python autograder.py -t test_cases/q4/1-disconnected-eliminate
提示和观察:
- 算法应该迭代消除顺序中的隐藏变量,对这些变量执行合并和消除操作,直到只剩下查询变量和证据变量。
- 输出因子的概率之和应为1,这样它才是一个条件在证据上的真正条件概率。
- 查看
inferenceByEnumeration函数在inference.py中的示例,了解如何使用所需的函数。(提醒:枚举推理首先对所有变量进行合并,然后消除所有隐藏变量。相比之下,变量消除通过迭代所有隐藏变量,在移动到下一个隐藏变量之前对单个隐藏变量执行合并和消除操作,从而交替进行合并和消除。) - 你需要处理一个特殊情况,即你合并后的因子只有一个非条件变量(文档字符串详细说明了如何处理)。
Q5a: DiscreteDistribution Class
不幸的是,加入时间步长会使我们的图变得过于复杂,不适合使用变量消除。因此,我们将使用 HMM 的前向算法进行精确推理,并使用粒子过滤进行更快但近似的推理。
在项目的其余部分,我们将使用 inference.py 中定义的 DiscreteDistribution 类来模拟信念分布和权重分布。这个类是内置Python字典类的扩展,其中键是分布中的不同离散元素,对应的值与分布赋予该元素的信念或权重成比例。本问题要求你填写该类中缺少的部分,这对后续问题至关重要(尽管本问题本身不计分)。
首先,填写 normalize 方法,该方法将分布中的值规范化,使其总和为1,但保持值的比例不变。使用 total 方法找到分布中值的总和。对于空分布或所有值均为零的分布,不做任何操作。请注意,该方法直接修改分布,而不是返回一个新分布。
其次,填写 sample 方法,该方法从分布中抽取一个样本,其中抽取某个键的概率与其对应值成比例。假设分布非空,并且所有值不全为零。请注意,在调用此方法之前,分布不必一定是规范化的。你可能会发现Python内置的 random.random() 函数对于这个问题很有用。